We rarely think about how we move. We just do it. However, creating a movement controller that matches our expectations is far more challenging than we would imagine (see Physics-based character animation and human motor control). Any roboticist will tell you. At Artanim we are exploring the use of movement controllers similar to the ones used to control robots, although doing so in physics simulations instead of in the real world. Our idea is that running these simulations in Virtual Reality (VR) will allow us to create characters with richer real-time reactivity. We believe this may be a step forward to improve the way autonomous virtual characters engage with their virtual environment, as well as a research path to provide characters that show lifelike behavior and some degree of nuanced interaction with VR users. Cognitive psychology and communication science has shown that people build rapport between them, in good part, through subtle behavioral cues, interpersonal coordination and loose but important rules relative to social space. Can we embed physics-based controllers with computational models that reproduce these mechanisms? (see Playing the mirror game in virtual reality with an autonomous character). What is the impact of implementing these computational models in VR experiences?
There are several technical challenges to address before we can explore questions related to interpersonal coordination and human-humanoid cooperation. The movement controllers need to be reliable, stable, solid, and easy to train, but also flexible enough to match the needs of a specific VR production scenario. Every day we engage with physical objects in rich and subtle ways: we grab a cup by its handle intuitively balancing it, use it to pour tea in it and drink it readapting dynamically to the movements of the liquid in it, then use the cup to push some object on the table, before leaving it there for a while. However, manipulating objects in tasks that require rich contacts is still a matter of fundamental research, in robotics and control theory. In addition, it is enough that we drink tea with someone else around for us to be willing to share the moment with them. We will change the dynamics involved in our gestures to show we take their interests and well-being into account. Can we create realistic social interactions among avatars and VR characters? This general question, focused specifically on body-centered interaction and interactive gestures, is what we are trying to answer in the EU Project PRESENCE.
Virtual avatars play a key role in many of our activities. They embody the actors in our productions, serve as reliable subjects in our machine learning efforts, or are the virtual bodies we inhabit when going on an adventure in one of our experiences. In cases where an avatar needs to represent a specific character or historical figure, the skilled work of our artists is often sufficient to create the final result.
Sometimes however we need a lot of variation. Whether this is to allow users to create avatars which more closely match their own appearance, or when creating datasets with an appropriate – and often overlooked – diversity for machine learning efforts. In such cases, the creation of tailor-made avatars is no longer feasible. It is with this in mind that we started what we call our Synthetic Factory efforts.
The basic premise of the Synthetic Factory is a simple idea. Given a neutral default character, and a set of outfits, footwear, and hair styles it can wear, can we create a set of size, shape, gender, and ethnicity changes which can be applied in real-time to create any subject we would like? The potential benefit is clear to see. Artists can simply design an outfit or a hairstyle which applies well onto a base model, and the Synthetic Factory would take care of the variations.
At the basis of the Synthetic Factory is a default avatar model. Artists can take this model and deform it to give it a certain characteristic. Whether this is a gender appropriate change in body type, a specific set of facial features, or an overall change in body size. The synthetic factory takes these inputs, as well as meta-data characterizing the “deformation”, and encodes them as blend shapes which can be applied on a weighted bases, smoothly blending between the original shape and the blend shape target. At runtime either a specific set of deformations and weights can be selected, or a set of broad characteristics can be supplied – such as “Female”, “Adult”, “Indian” for example – after which random deformations and weights are selected which are appropriate for those characteristics.
The base model (center) with 2 of its 80 blendshape.
Any assets applied on top of this model, be they outfits, footwear, hair styles and the like, need to be able to deform appropriately given any changes made to the body blend shapes. The Synthetic Factory automates this process in a pre-processing step. After applying the asset to the neutral base model, a mapping is created, encoding how the asset fits the model. Once this mapping is complete, the factory runs through all the body blend shapes, and then determines how the asset needs to deform to keep the appropriate mapping in relation to the body.
Three avatars wearing the same outfit at 3 different proportions.
These deformations are then once again stored as blend shapes, this time as a part of the asset. This precomputation happens once, and at runtime no further heavy computation is required. All assets get annotated with a set of meta-data, making sure they are only ever combined in a way matching the model’s chosen characteristics.
As a part of its run-time tools, the Synthetic Factory also enables the modification of the skeleton driving the avatar. Either through specification of exact body measurements which match a specific dataset, or by supplying an overall target height, what we call the “AvatarBuilder” will generate a new skeleton matching the requirements and applies it to the Avatar.
Combine these tools with more fine-grained randomizations such as appropriate skin tones, as well as color and texture randomizations on outfits, and from a relatively compact set of basic inputs you have the ability to generate a large variety of diverse avatars fit for any purpose. In the video below, you can see the result for 36 randomly created avatars based on gender, age and ethnicity input.
The third year of VRTogether is in full swing, and despite the recent pandemic scare our consortium is hard at work creating the technology and content for our third-year pilot. As we have described before, pilot 3 will involve an interactive scenario where users take on an active role trying to solve the mysterious murder of Elena Armova.
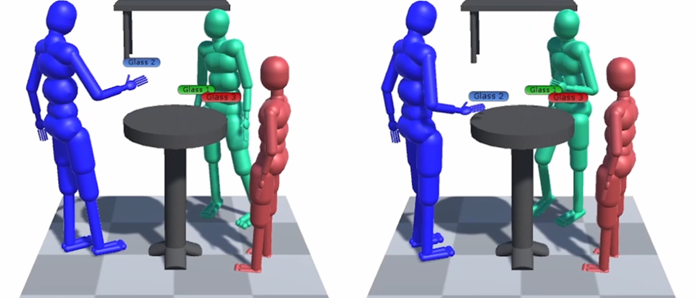
Pilot 1 involved a one-take interrogation scene observed by our users, and was created using three different content formats; 360 degree video, a 3D scene with billboard video, and a 3D scene with 3D characters. For this last option the actors were captured using a custom photogrammetry rig from Artanim with more than 90 cameras, after which their 3D mesh was reconstructed and subsequently rigged and animated using mocap data. The three formats allowed us to evaluate their tradeoffs in a VR context. The results indicated that in general the video billboards were preferred by users for their visual quality and natural appearance, but their main shortcoming is that user movement is very limited before such billboards no longer maintain their illusion.
Pilot 3 puts the users at the scene of the crime. Standing at and moving between different locations in Elena Armova’s apartment, they observe and interact with the characters in the scene. This, given the aforementioned shortcomings of a video billboard solution, means we will see the return of 3D characters. An additional downside of a billboard solution would have been the difficulty to have a seamless continuity of a variety of recordings. The interactivity inherent to the plot will see our characters respond to our user’s actions, wait for their response and progress along several possible paths. To seamlessly blend these various branches in our timeline, the only truly feasible option is to opt for 3D characters, driven by a full performance capture (motion capture for the full body including the fingers and face).
Having evaluated the 3D characters of Pilot 1, the consortium wanted to aim for a higher visual quality for Pilot 3. While a commercial 3D photogrammetry solution has been considered, both financial and scheduling constraints made this impractical. Luckily content creation solutions have not stopped evolving over the last few years, among which Reallusion’s Character Creator ecosystem – as well as other tools – which will be used to create our 3D characters. Characters created with the tools in this ecosystem are easily animated in real-time 3D engines such as Unity, by motion capture data from the body and hands all the way to facial animation.
Besides executing the motion capture, Artanim and its artists have taken on the task of creating our high quality virtual characters. The first step in the process is the collection of as much reference material as possible. The COVID-19 pandemic made taking in-studio headshots impossible, but some of the actors involved were already photographed as a part of pilot 1, while others supplied as much reference material as they possibly could. This includes high quality photos of their head from all angles, full body shots, as well as a set of body measurements to make sure their virtual counterparts match their own morphology. Ensuring a close match between the two also simplifies the retargeting stage while post-processing the motion capture.
Reference headshots of actor Jonathan D. Mellor who plays the character of Sarge.
Modern AI approaches have evolved quite significantly in recent years, leading to major advances in image processing in general, and obtaining 3D information from monocular views in particular. These developments find their way into content creation tools such as Character Creator’s Headshot AI plugin used as a basis for our character’s heads. Such tools do a commendable job based on a single image from a single view, but the creation of a more correct likeness still involves quite a lot of manual work, taking the generated output as a basis, carefully modifying the obtained 3D mesh to more closely match our actors’ morphologies.
The AI-generated output (left) needs significant artist intervention to get a good likeness (right), in particular for faces with asymmetrical features.
This is then followed by the addition of hair geometry, textures, shaders and materials to get a final real-time VR ready result.
After the addition of hair, textures and material setup, Sarge’s head is complete.
Without the use of 3D scans, the creation of the body is still a largely artistic process. Starting from a basic avatar body, it is up to the artist to adjust the basis to the actor’s appropriate sizes, and to adapt or model 3D clothing and accessories – including meshes, textures and materials – to get a high quality end result.
The end result is a high quality 3D representation of our actors, which can be used in interactive real-time VR scenarios for an exciting immersive experience.
Do you feel in control of the body that you see? This is an important question in virtual reality (VR) as it highly impacts the user’s sensation of presence and embodiment of an avatar representation while immersed in a virtual environment. To better understand this aspect, we performed an experiment in the framework of the VR-Together project to assess the relative impact of different levels of body animation fidelity to presence.
In this experiment, the users are equipped with a motion capture suit and reflective markers to track their movements in real time with a Vicon optical motion capture system. They also wear Manus VR gloves for fingers tracking and an Oculus HMD. At each trial, the face (eye gaze and mouth), fingers and the avatar’s upper and lower bodies are manipulated with different degree of animation fidelity, such as no animation, procedural animation and motion capture. Each time, users have to execute a number of tasks (walk, grab an object, speak in front of a mirror) and to evaluate if they are in control of their body. Users start with the simplest setting and, according to the judged priority, improve features of the avatar animation until they are satisfied with the experience of control.
Using the order in which users improve the movement features, we can assert on the most valuable animation features to the users. With this experiment, we want to confront the relative importance of animation features with the costs of adoption (monetary and effort) to provide software and use guidelines for live 3D rigged character mesh animation based on affordable hardware. This outcome will be useful to better define what makes a compelling social VR experience.
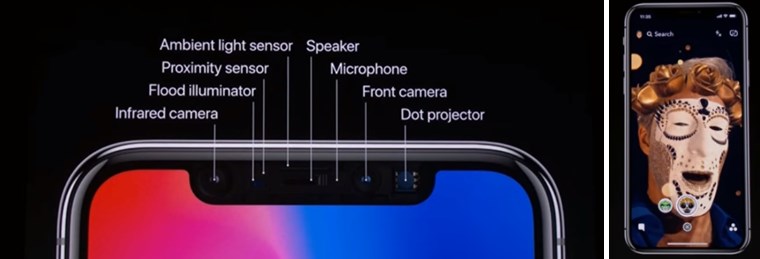
We will soon start shooting cinematic content to be used for showcasing the technology developed by the VR-Together consortium. In this post, we bring some of the production effort developed at Artanim, which is currently exploring the use of Apple’s iPhone X face tracking technology in the production pipeline of 3D animations.
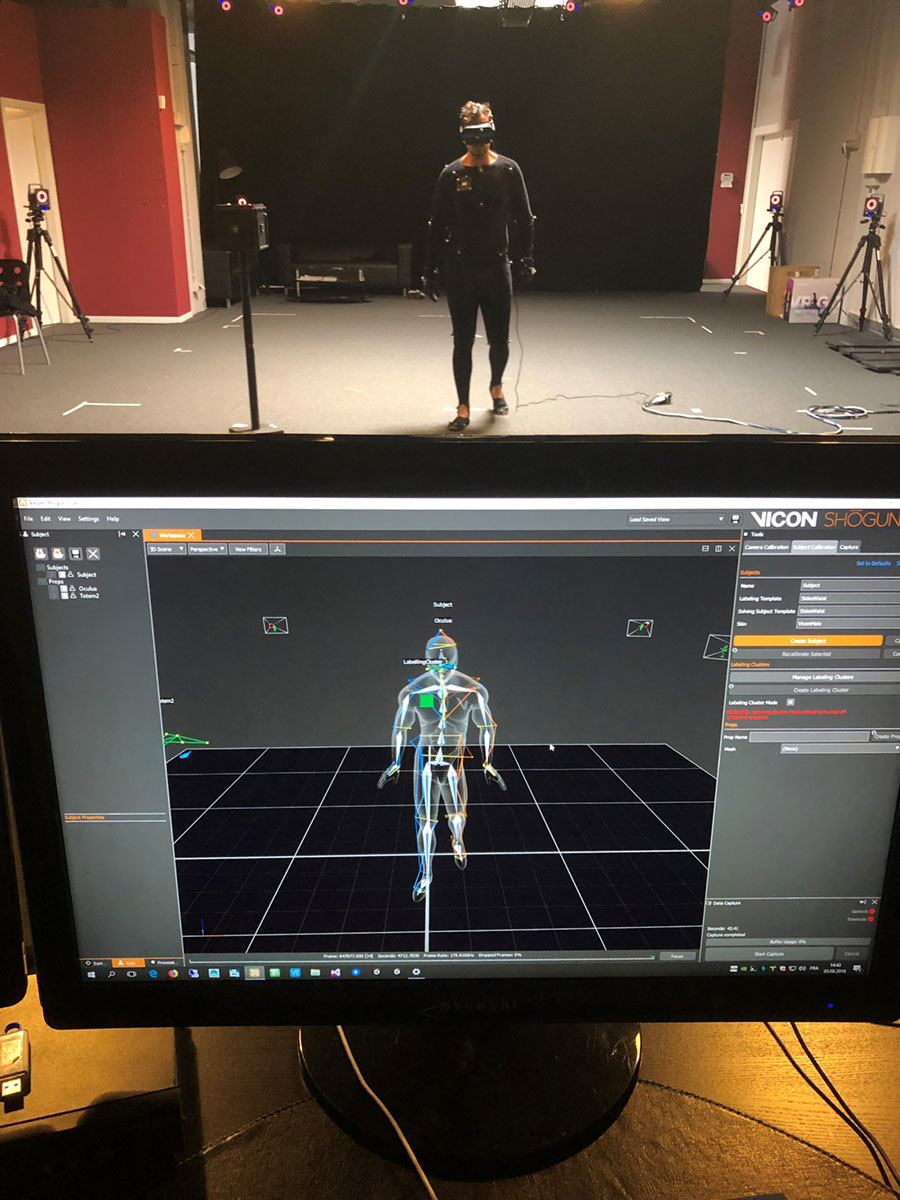
The photos below show the iPhone X holding rig, and an early version of the face tracking recording tool that was developed by Artanim. The tool integrates with full body and hands motion capture technology from Vicon to allow the simultaneous recording of body, hands and face performance from multiple actors.
With the recent surge of consumer virtual reality, interest for motion capture has dramatically increased. The iPhone X and ARKit SDK from Apple integrate depth sensing and facial animation technologies, and are a good example of this trend. Apple’s effort to integrate advanced face tracking to their mobile devices may be related to the recent acquisition of PrimeSense and FaceShift. The former was involved in the development of the technology powering the first Kinect back in 2011, the latter is recognized for their face tracking technology, which is briefly showcased in the making of Star Wars: The Force Awakens trailer. These are exciting times, when advanced motion tracking technologies are becoming ubiquitous in our life.
Image from the iPhone X keynote presentation from Apple
Artanim just added a new tool to its motion capture equipment: the Optitrack Insight VCS, a professional virtual camera system. From now on, everyone doing motion capture at Artanim will be able to step into the virtual set, preview or record real camera movement and find the best angles to view the current scene.
The motion capture data captured by our Vicon system is processed in real time in MotionBuilder and displayed on the camera monitor. The position of MotionBuilder’s virtual camera is updated by the position of the reflective markers on the camera rig. In addition, the camera operator can control several parameters such as the camera zoom, horizontal panning, etc. The rig itself is very flexible and can be modified to accommodate different shooting styles (shoulder-mounted, hand-held, etc.).
We can’t wait to use it in future motion capture sessions and show you some results. Meanwhile, you can have a look at our first tests in the above video.