We rarely think about how we move. We just do it. However, creating a movement controller that matches our expectations is far more challenging than we would imagine (see Physics-based character animation and human motor control). Any roboticist will tell you. At Artanim we are exploring the use of movement controllers similar to the ones used to control robots, although doing so in physics simulations instead of in the real world. Our idea is that running these simulations in Virtual Reality (VR) will allow us to create characters with richer real-time reactivity. We believe this may be a step forward to improve the way autonomous virtual characters engage with their virtual environment, as well as a research path to provide characters that show lifelike behavior and some degree of nuanced interaction with VR users. Cognitive psychology and communication science has shown that people build rapport between them, in good part, through subtle behavioral cues, interpersonal coordination and loose but important rules relative to social space. Can we embed physics-based controllers with computational models that reproduce these mechanisms? (see Playing the mirror game in virtual reality with an autonomous character). What is the impact of implementing these computational models in VR experiences?
There are several technical challenges to address before we can explore questions related to interpersonal coordination and human-humanoid cooperation. The movement controllers need to be reliable, stable, solid, and easy to train, but also flexible enough to match the needs of a specific VR production scenario. Every day we engage with physical objects in rich and subtle ways: we grab a cup by its handle intuitively balancing it, use it to pour tea in it and drink it readapting dynamically to the movements of the liquid in it, then use the cup to push some object on the table, before leaving it there for a while. However, manipulating objects in tasks that require rich contacts is still a matter of fundamental research, in robotics and control theory. In addition, it is enough that we drink tea with someone else around for us to be willing to share the moment with them. We will change the dynamics involved in our gestures to show we take their interests and well-being into account. Can we create realistic social interactions among avatars and VR characters? This general question, focused specifically on body-centered interaction and interactive gestures, is what we are trying to answer in the EU Project PRESENCE.
Dreamscape Announces Breakthrough VR Tech Upgrade Enabled by Vicon’s Markerless Motion Tracking System
New location-based VR technology to launch at Dreamscape’s Geneva flagship store in partnership with Swiss research partner, Artanim
GENEVA – 28th of March 2025 – Today marks a new era of innovation in the field of Location Based Entertainment (LBE) for Dreamscape, the award-winning VR group. The company announced it will launch its latest Location Based Virtual Reality (LBVR) experience at its Geneva flagship store, powered by brand new machine learning-based markerless technology from motion capture leader, Vicon. The VR technology bringing the experience to life was developed in collaboration with Artanim, the Swiss research institute.
For Dreamscape, markerless motion capture can now provide a more true-to-life adventure than any other immersive VR experience by allowing for more free-flowing movement and exploration with even less user gear. In addition to smoother user journeys, this technological upgrade also has a major impact on staff operations and will ultimately facilitate Dreamscape’s international locations roll-out.
This new technology, presented exclusively in Geneva, will be implemented across all industry sectors where Dreamscape is active including Entertainment, Education and Corporate solutions.
Commenting on the news, Caecilia Charbonnier, Co-founder & CIO of Dreamscape and co-founder & Research Director of Artanim, said: “We’ve long anticipated the moment when markerless motion capture could transition from concept to reality, reaching the level of precision needed to unlock its full potential. With Vicon’s decades-long legacy of setting the gold standard in motion capture technology and Dreamscape’s unwavering mission to create seamless, immersive experiences, our collaboration on this project was a natural fit.”
The opening of the new Dreamscape experience comes on the heels of Vicon’s announcement regarding its markerless motion capture launch on March 11. The company showcased the technology at the Game Developers Conference in San Francisco following years of R&D at its renowned facilities in Oxford, UK. The project leverages nearly four decades worth of Vicon innovation to enable seamless, markerless motion capture.
“Collaborating with Dreamscape on this project offered Vicon a unique opportunity to continue our work with a world leader in LBVR and demonstrates the value of our markerless motion capture technology,” said Vicon CEO, Imogen O’Connor. “This is only the beginning. Vicon’s system is a first-of-its-kind platform for markerless motion capture for creators, story tellers and 3D artists across LBVR, game, film and episodic TV.”
The collaboration between Vicon and Artanim was key to ensure the desired requirements for the VR use case were met.
“Delivering best in class virtual body ownership and immersion in VR demands both accurate tracking and very low latency,” said Sylvain Chagué, co-founder and CTO of Artanim and Dreamscape. “We dedicated substantial R&D efforts to evaluating computational performance of machine learning-based tracking algorithms, carefully implementing and refining this multi-modal tracking solution – seamlessly integrating full-body markerless motion capture and VR headset tracking for an unparalleled experience.”
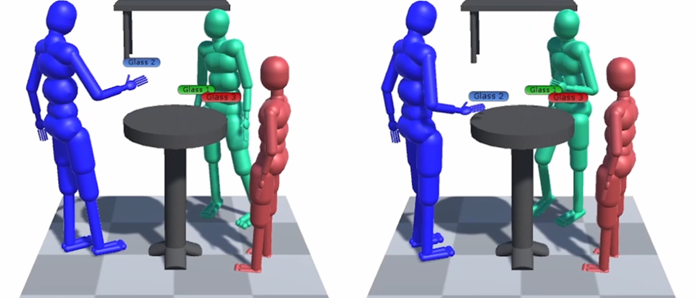
This breakthrough technology will be premiered at Dreamscape Geneva, showcasing a six person, markerless, and multi-modal real-time solve, set against Dreamscape’s LBVR adventure entitled The House of Wonders. Created in partnership with Swiss Haute Horlogerie manufacturer Audemars Piguet, this experience delves participants into the hidden depths of enchanting workshops, where they meet a cast of passionate artisans and participate in the creation of a mechanical marvel.
More information about the collaborative R&D project here.
Artanim, expert in the creation of immersive experiences, launched its new historic adventure on December 6th, 2023 in partnership with the Compagnie de 1602, showcased exclusively at the Dreamscape center in Geneva.
Building on the success of Geneva 1850, Artanim invites this time the inhabitants of Geneva on a journey through time, plunging them into the heart of the emblematic night of the Escalade of 1602. This immersive experience was designed in close collaboration with theCompany of 1602 which provided its expertise by participating in the development of the script to guarantee its authenticity.A wide range of costumes, armor, period objects, and even professional performers, have been made available by the Company to allow an immersion as precise as possible.
Escalade – The darkest Night will replace Geneva 1850, the result of the partnership between Artanim and the Museum of Art and History of Geneva, which offered a virtual immersion in Geneva in the mid-19th century.This experience, which was acclaimed by Genevans, was offered in 2019 at Maison Tavel, then was revisited and brought up to date for the opening of the Dreamscape Geneva center in July 2022.
The adventure scents, including the scent of the soup of the Mère Royaume and the scent of torches, were designed in partnership with DSM-Firmenich.
The production was supported by Ernst Göhner Foundation, CCIG and Synergix.
Vicon debuts its markerless motion capture technology in collaboration with Artanim, the research arm of Dreamscape, the leading VR company, at SIGGRAPH 2023
Vicon today marks a new era of innovation in the field of motion capture, announcing that it will debut its machine learning (ML) powered markerless technology at SIGGRAPH 2023 in Los Angeles, in collaboration with Artanim, the Swiss research institute and the award-winning VR group, Dreamscape Immersive.
The announcement follows nearly three years of research and development focusing on the integration of ML and artificial intelligence (AI) into markerless motion capture at Vicon’s renowned R&D facility in Oxford, UK. The project has been undertaken by a new dedicated team, led by CTO Mark Finch, and leverages nearly four decades worth of Vicon innovation to enable a seamless, end-to-end markerless infrastructure, from pixel to purpose.
Commenting on the news, Imogen Moorhouse, Vicon CEO, said:
“Today marks the beginning of a new era for motion capture. The ability to capture motion without markers, while maintaining industry leading accuracy and precision, is an incredibly complex feat. After an initial research phase, we have focused on developing the world class markerless capture algorithms, robust real time tracking, labeling and solving needed to make this innovation a reality. What we are demonstrating at SIGGRAPH is not a one-off concept, or simply a technology demonstrator. It is our first step towards future product launches which will culminate in a first-of-its-kind platform for markerless motion capture.”
For Dreamscape, markerless motion capture can now provide a more true-to-life adventure than any other immersive VR experience by allowing for more free-flowing movement and exploration with even less user gear. Commenting on the decision to partner with Vicon, Aaron Grosky, President & COO of Dreamscape said:
“We have been anxiously awaiting the time when markerless could break from concept and into product, where the technology could support the precision required to realize its amazing potential. Vicon’s reputation for delivering the highest standards of motion capture technology for nearly forty years and Dreamscape’s persistent quest to bring the audience into the experience with full agency and no friction meant that working together on this was a no-brainer. We’re thrilled with the result. The implications for both quality of experience and ease of operations across all our efforts, from location-based entertainment to transforming the educational journey with Dreamscape Learn, is just game-changing.”
The collaboration between Vicon and Artanim was key to ensure the desired requirements for the VR use case were met.
“Achieving best in class virtual body ownership and immersion in VR requires both accurate tracking and very low latency. We spent substantial R&D effort evaluating computational performance of ML-based tracking algorithms, implementing and fine-tuning the multi-modal tracking solution, as well as taking the best from the full-body markerless motion capture, and VR headset tracking capabilities,” said Sylvain Chagué, co-founder and CTO of Artanim and Dreamscape.
At SIGGRAPH, Vicon and Artanim showcased a six person, markerless and multi-modal real-time solve, set against Dreamscape’s location-based virtual reality adventure called The Clockwork Forest, created in partnership with Audemars Piguet, the Swiss haute horology manufacturer. The experience allows participants to shrink to the size of an ant and explore a mechanical wonderland, while working together to repair the Source of Time and restore the rhythm of nature.
With this showcase, Vicon earned a CGW Silver Edge Award for technological innovation. More information about the collaborative R&D project here.
Created in 2012, the Great Economy Awards aim to promote and enhance the economic sector of Geneva.They also aim to honor companies whose reputation and influence convey a positive and dynamic image of Geneva.
During the Great Economy Awards, held on September 20, 2022 at the BFM, the 2022 Geneva Economy Prize was awarded to Spineart, a pioneer in procedures and medical devices related to spine surgery.The 2022 Innovation Prize was awarded to Kugler Bimetal, which specializes in high-performance materials.The Equality Prize, created last year, was awarded to the Moser School for the measures implemented to ensure equality.Finally, the jury made up of 13 personalities from the academic and economic worlds chose to award a Special Prize to the Artanim Foundation, a leader in motion capture technologies.
These Prizes were awarded by the Geneva Chamber of Commerce, Industry and Services (CCIG), the State of Geneva and the Office of Promotion of Industries and Technologies (OPI).